
TermSuite UIMA Type System
The Type System is the schema of UIMA annotations contained in the CAS (Common Abstract Structure) passed to all analysis engines of the UIMA pipeline. This section presents the Type System used by TermSuite Preprocessor pipeline, i.e. our data model at Step 1 of terminology extraction.
There are three annotation types in TermSuite. See TermSuite Type System XML file for an up-to-date view of the type system.
SourceDocumentInformation: exactly one per document, i.e. per CAS, containing all metadata needed about the current textual document being processed,WordAnnotation: a word, or a punctuation element,TermOccAnnotation: a term occurrence detected by Term Spotter.
org.apache.uima.examples.SourceDocumentInformation
uri:StringoffsetInSource:IntegerlastSegment:BooleandocumentSize:IntegercorpusSize:IntegercumulatedDocumentSize:IntegerdocumentIndex:IntegernbDocuments:Integer
fr.univnantes.termsuite.types.WordAnnotation
stem:Stringlemma:Stringgender:Stringcase:Stringmood:Stringtense:Stringtag:Stringformation:Stringdegree:Stringcategory:StringsubCategory:Stringperson:Stringpossessor:StringregexLabel:Stringlabels:String
fr.univnantes.termsuite.types.TermOccAnnotation
termKey:Stringword:WordAnnotation[]pattern:StringArray(an array of UIMA Tokens Regex labels)spottingRuleName:String(the name of the UIMA Tokens Regex rule that spotted this term)
Terminology Data Model
This section presents the data model used by TermSuite terminology extractor pipeline and TermSuite Java API, i.e. our data model at Step 2 of terminology extraction.
Class diagram
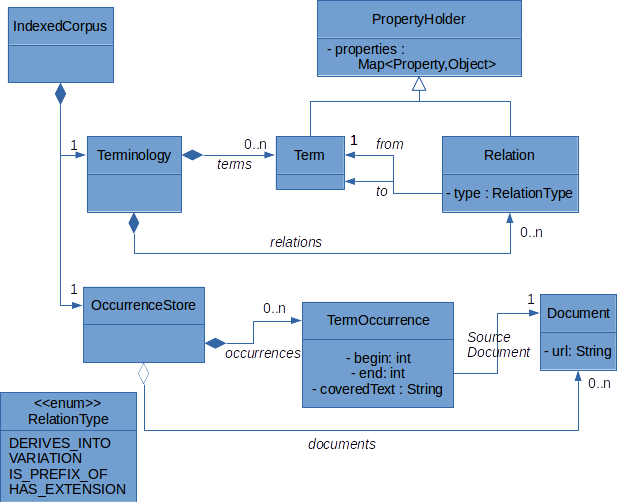
As any graph structure, a Terminology is a container for a collection of Terms (the nodes) and a collection of Relations (the edges). Both Terms and Relations are PropertyHolders, ie. every term and relation has a set of properties held in a key-value store.
As TermSuite has the ability to keep track of all terms occurrences while they are spotted and gathered. This is the purpose of the OccurrenceStore, which holds a collection of Documents and TermOccurrences.
The IndexedCorpus simply is a container for the Terminology and its OccurrenceStore.
Relation types
As illustrated in class diagram above, relations are typed. There are currently four types of relation:
VARIATION: this is the most probably the only relation type interesting for terminology explotation. At the time of writing, all other relation types are mostly intended to analysis engines of the terminology extraction process. For example, information about term derivation, term prefixation, and term extensions are reified in relations of type VARIATION as properties (see isDeriv, isPref, and isExt)DERIVES_INTO: This relation is set between two single-word terms whenever an atomic derivation has been detected by the DerivationGatherer (see term gatherer).IS_PREFIX_OF: This relation is set between two single-word terms whenever an atomic prefixation has been detected by the PrefixationGatherer (see term gatherer).HAS_EXTENSION: This relation is set between two terms whenever an extension has been detected by the DerivationGatherer (see preparator). TheHAS_EXTENSIONis purely an inclusion of sequences (the sequence of term’s words) between two terms. It is “variant agnostic” in the sense there can be a HAS_EXTENSION relation between two terms even though there are not variants.