
TermSuite is a tool for working on domain-specific term. It implements two major features: Terminology extraction and Bilingual alignment. This page gives an overview of their architectures.
Terminology Extraction (Steps 1 and 2)
Terminology extraction is the process of producing an exhaustive list of domain-specific
terms from a corpus of textual documents dealing with this domain.
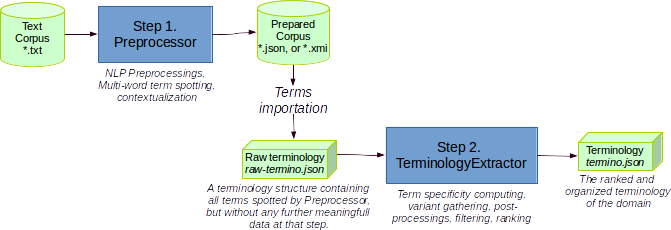
As show by the figure above, terminology extraction is a two-step process:
- [Step 1. Preprocessor*](#preprocessor): every textual document of the corpus is analyzed
by an UIMA-based NLP (Natural Language Processing*) pipeline that spots all candidate terms
in the document. - Step 2. TerminologyExtractor: spotted terms are analyzed, gathered, filtered,
and ranked by specificity to the domain.
The preprocessed documents produced by Preprocessor comes out as a corpus of UIMA annotations, called a prepared corpus, in XMI or JSON. The TerminologyExtractor is a pipeline that operates on a terminology structure. The process of transforming a prepared corpus into a terminology is named term importation and consists in gathering all occurrences of the same term key into a single terminology structure.
Step 1: Preprocessor
Preprocessing is the process of transforming a text, i.e. a String data, into a list of UIMA annotations, including term occurrences. It is a mandatory step before terminology extraction, but you can reuse TermSuite natural language preprocessings in any other application context (not only on terminology extraction).

The framework used by TermSuite for its NLP pipeline is UIMA. See TermSuite UIMA Type System to get an idea on how the tokens (UIMA annotations) are modelled within TermSuite.
Word tokenizer
Transforms a text, i.e. a String, into a list of tokens, i.e. words and punctuations. TermSuite ships its own UIMA tokenizer.
| Source code: | UIMA tokenizer |
| Resource: | SegmentBank |
POS Tagger and Lemmatizer
of a term,
The POS Tagger attributes a syntactic label to each token. The Lemmatizer sets the lemma of each word.
POS tagging and lemmatizing are often performed together in the same module. There are two POS taggers/lemmatizers supported by TermSuite:
- TreeTagger, (default)
- Mate.
These bricks need to be installed apart from TermSuite. See how to install POS tagger/lemmatizer in TermSuite.
For TreeTagger:
| Source code: | TreeTagger UIMA wrapper |
| Resource: | TreeTaggerConfig |
For Mate:
| Source code: | Mate UIMA wrapper |
| Resource: | (No TermSuite resource required for this module) |
Tag normalization
Normalizing is the process of translating each POS tag into MULTEXT universel tag set.
When TreeTagger is used:
| Source code: | TreeTagger UIMA normalizer |
| Resources: | CategoryMapping, SubCategoryMapping, TenseMapping, MoodMapping, GenderMapping, NumberMapping, CaseMapping |
When Mate is used:
| Source code: | Mate UIMA normalizer |
| Resources: | CategoryMapping, SubCategoryMapping, TenseMapping, MoodMapping, GenderMapping, NumberMapping, CaseMapping |
Stemmer
Stemming is the process of extracting the stem form of each word. TermSuite ships its own UIMA stemmer, implementing Snowball.
| Source code: | UIMA Snowball Stemmer |
| Resource: | (No TermSuite resource required for this module) |
Term Spotter
Term spotting is the process of parsing a sequence of words and detecting wich subsequences are term occurrences. TermSuite performs pattern-based multi-word term spotting with the help of UIMA Tokens Regex engine and a list of regex rules on UIMA annotations. UIMA Tokens Regex is a generic regex rule system for sequential UIMA annotations. It has been designed and implemented especially with the goels of TermSuite in mind.
| Source code: | Term Spotter |
| Resource: | MultiWordRegexRules |
Multi-word term detection in TermSuite is rule-based, based on syntactic term patterns. Each supported language has its own exhaustive list of allowed term patterns. Read UIMA Tokens Regex documentation and TermSuite demo paper at ACL for more information about this process.
Importation of spotted terms into terminology
Once the preprocessor has operated on all documents of the corpus, all their spotted term occurrences must be grouped into one single place: the terminology. This step is called Importation.
The importation consists in iterating on all spotted term occurrences of all documents. Two different occurrences are said to belong to the same term if they share the same grouping key. The grouping key is defined as the concatenation of the syntactic pattern of the and its word lemmas. For example:
n: blade: possible forms of spotted occurrences for this term could be blade, blades, Blade, etc.nn: rotor blade: possible forms of spotted occurrences for this term could be rotor blade, rotor blades, etc.npn: energy of wind: possible forms of spotted occurrences for this term could be energy of wind, energy of the wind. As you can see, determiners like the are ignored when it comes to grouping occurrences under the same term pattern.
With command line API, this importation phase between preprocessing and terminology extraction is operated automatically either:
- at the end of the preprocessing phase when the user launches the
PreprocessorCLIscript with option--json PATH, - or at the beginning of ther terminology extraction phase when the user launches the
TerminologyExtractorCLIscript with either option--from-prepared-corpus PATH, meaning that PATH points to a directory containing prepared documents files (*.xmior*.json) that are the output ofPreprocessorCLIwhen run with option--xmi-anno PATHor--json-anno PATH. - Or at the middle of the preprocessing+extraction phase when the user launches the
TerminologyExtractorCLIwith option--from-text-corpus PATH, meaning that TermSuite first runs a preprocessor internally, then import spotted occurrences to a terminology, and finally runs the terminology extraction process on that terminology.
With Java API, the importation phase can also be performed manually.
Step 2: Terminology extraction
The terminology extraction consists in taking as input an imported terminology an applying the folowing pipeline:
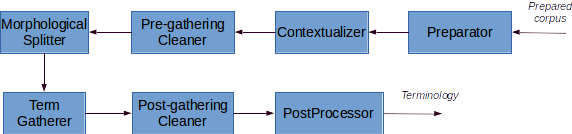
This global extraction pipeline is implemented in class TerminologyExtractorEngine.
Preparator
The Preparator operates a series of simple actions on the terminology that are required for later steps of the terminology extraction:
- validition of the input terminology,
- computation of some term properties, including specificity, lemma, pilot, document frequency, swtSize,
- computation of some term relations, including extensions, (see Terminology Data Model).
| Source code: | Terminology Preparator |
| Resource: | GeneralLanguageResource |
Contextualizer
The Contextualizer produces a context vector for each single-word term. It requires no linguistic resource. Term occurrences of each term are required for contextualization.
| Source code: | Terminology Preparator |
| Resource: | (No TermSuite resource required for this module) |
Pre-gathering cleaner
The Pre-gathering cleaner is a hook allowing the user to configure a terminology filtering before the term gathering process is performed. The interest of filtering before the term variant gathering is that
| Source code: | TerminologyCleaner |
| Resource: | (No TermSuite resource required for this module) |
See --pre-filter-* options of command line API in order to configure the pre-gathering filter.
Morphological Splitter
The Morphological Splitter analyzes the morphology of every single-word term and splits it when compound. The Morphological Splitter is an aggregation of several modules.
- The PrefixSplitter detects prefixes and splits terms accordingly.
| Source code: | PrefixSplitter |
| Resources: | PrefixBank, PrefixExceptions |
- The ManualSplitter detects word composition based on a known list of word composition and splits terms accordingly.
| Source code: | ManualPrefixSetter |
| Resources: | ManualCompositions, PrefixExceptions |
- The SuffixDerivationDetecter detects derivations based on list of language-specific derivation rules and splits terms accordingly:
| Source code: | PrefixSplitter |
| Resources: | SuffixDerivations, SuffixDerivationExceptions |
- The NativeSplitter detects derivations based on list of language-specific derivation rules and splits terms accordingly. It implements the method ComPost. The NativeSplitter is the one responsible for detecting neoclassical compounds.
| Source code: | NativeSplitter |
| Resources: | CompostInflectionRules, CompostTransformationRules, NeoclassicalPrefixes, CompostStopList, CompostDico |
Term Gatherer
The Term Gatherer is in charge of grouping terms with their variants. It is based on a list of variation rules. The term gatherer is also an aggregated engine. It is composed of several subengines.
- The PrefixationGatherer detects variations based on prefixes compositions of some terms (extracted at Morphological Splitter phase by PrefixSplitter)
| Source code: | PrefixationGatherer |
| Resource: | YamlVariantionRules |
-
The DerivationGatherer detects variations based on derivation relations extracted by DerivationSplitter
Source code: DerivationGatherer Resource: YamlVariantionRules -
The MorphologicalGatherer detects variations based on native and neoclassical compositions (extracted at Morphological Splitter phase by NativeSplitter)
Source code: MorphologicalGatherer Resource: YamlVariantionRules -
The SyntagmaticGatherer detects all other type of syntagmatic variations that do not require special processing like prefixes, derivations, synonyms, and morphological compounds.
Source code: SyntagmaticGatherer Resource: YamlVariantionRules -
The SemanticGatherer detects semantic variants from a list of synonymic rules based on both a distributional approach and a dictionary.
Source code: SemanticGatherer Resources: YamlVariantionRules, Synonyms -
The ExtensionVariantGatherer gather long terms with their variants using inference on term extensions and variations for shorter terms.
Source code: ExtensionVariantGatherer Resource: (No TermSuite resource required for this module) -
The GraphicalGatherer gathers terms having a small edition distance.
Source code: GraphicalGatherer Resource: (No TermSuite resource required for this module) -
The TermMerger merges some terms with their variants each time the variation is not relevant. A variation is not relevant when its graphical similarity is 1 or when the variant’s frequency is 1 or 2.
Source code: GraphicalGatherer Resource: (No TermSuite resource required for this module)
Post-gathering cleaner
The Post-gathering cleaner is a hook allowing the user to configure a terminology filtering after the term gathering process has been performed. The interest of filtering after term gathering is to keep terms that would not pass the filter normally but that are variants of base terms that we want to keep.
| Source code: | TerminologyCleaner |
| Resource: | (No TermSuite resource required for this module) |
See --post-filter-* options of command line API in order to configure the pre-gathering filter.
PostProcessor
The post-processor filters terms and variations based on information derived from the gathering process. It works with no linguistic resources. It is also an aggregated engine, composed of the following subengines.
- IndependanceScorer
- OrthographicScorer
- VariationScorer
- ThresholdExtensionFilterer
- VariationFiltererByScore
- TwoOrderVariationMerger
- TermFiltererByScore
- VariationRanker
Bilingual Alignment (Step 3)
Finding the best translation of a domain-specific source term into a target language is called bilingual alignement. Domain-specific bilingual alignement in TermSuite requires:
- a bilingual dictionary from the source language to the target language,
- a source contextualized terminology, i.e. a terminology extracted from a corpus of the domain in source language,
- a target contextualized terminology, i.e. a terminology extracted from a corpus of the domain in target language.
- a source term that will be translated into target language.
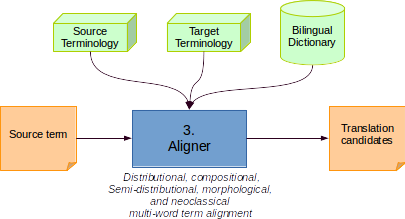
Bilingual alignement of source term in TermSuite is the result of a multi-part and hierarchical algorithm. The source term can be of several types: single-word term, multi-word term, compound term, neoclassical term, etc. Depending on this type, the alignment method invoked by TermSuite is not the same.
See also:
- aligner command line API to learn how to launch bilingual alignment,
- how to extract an alignment-ready terminology with TermSuite,
- theoritical insights on different bilingual alignment methods used by the algorithm,
- an example of bilingual dictionary required for alignment.